|
就在刚刚,Anthropic又出手了! Claude Code之父重磅官宣:Claude Code新增代码评审(Code Review)新功能。 这一次,它瞄准了一个价值500亿美元的产业——代码安全审计。 Anthropic刚刚发布的新功能,可以说是在用极其简单粗暴的方式,直接挑战整个代码安全行业。 有人惊呼:价值500亿美元的行业,被Anthropic一夜干翻了! 现在,可以坐等安全股大跌了。 在Anthropic,几乎每个PR都测试了此系统。 经过数月的测试,结果如下: 包含实质性评审意见的PR比例从16%增加到54%。   工程师认为评审结果错误的比例不到1%。 在大型Pull Request(1000行以上)中,84%的PR存在表面问题,平均每份PR存在7.5个问题。 目前,该功能已给Claude Team和Enterprise测试版中作为研究预览上线。  500亿美金市场的噩梦 Anthropic的这个产品,简直是让全球AI圈和网络安全界(AppSec)发生了一场足以载入史册的大地震。 资深开发者纷纷惊呼,价值500亿的代码审计行业被端了! 这是因为,在过去,大公司为了防止代码里的Bug或安全漏洞流向生产环境,每年要支付给传统安全厂商(如Snyk、Checkmarx 等)高达5万美金甚至更高的授权费,雇佣专业团队进行扫描和审计。 而现在,Claude却可以直接派一队AI智能体潜伏在你的PR里,24小时待命。 而且,按token计算,它的单次Review成本,平均只要15-25美元! 5万美金和25美金,差了2000倍。 这根本不是功能更新,这是给传统代码审计吹响了终结的号角。    Code Review,开发者最痛苦的环节 如果你问一个任何一个工程团队:软件开发中最大的瓶颈环节,是哪一个? 相信很多人的答案,都是代码评审(Code Review)。 过去几年,AI写代码的能力是日新月异,突飞猛进,无论是GitHub Copilot、Cursor、Claude Code还是ChatGPT,用上这些工具的开发者,写出的代码量直接暴涨。 结果,问题来了——虽然代码被飞速产出,审代码的人却并没有变多。 Anthropic发现,过去一年里,每位工程师的代码产出增加了200%,但很多PR(Pull Request)只是被快速扫了一眼。 连开发者自己都承认,很多代码评审,不过是在走流程而已。 于是,大量Bug、漏洞、逻辑问题就这样被带进生产环境。 这也就是为什么,很多企业愿意花天价去买安全扫描工具。 然而问题来了——这些工具并不聪明。 传统代码扫描工具,到底有什么问题? 如果你用过传统AppSec工具,比如Snyk、Checkmarx、Veracode、SonarQube等,你大概率会有这样的感受:误报太多了。 原因在于,这些工具大多数基于静态规则和已知漏洞库,可以扫描代码,却无法真正理解代码。 经常发生的一个场景,就是工具提醒“可能有SQL注入风险”,开发者检查了半天,却发现没有问题。 于是大家慢慢开始忽略警告,而真正危险的问题,就往往被忽略过去。 因此,企业仍然需要大量人工Code Review,而Anthropic这次做的,就是把它自动化。 Anthropic,扔出一个AI代码评审军团 这一次,Claude Code Review的思路其实很简单。 在Claude Code中,系统可以自动分析Pull Request,并从多个角度进行检查,例如: 代码规范是否符合项目规则 是否存在潜在bug 修改是否与历史代码逻辑冲突 之前PR中提出的问题是否再次出现 最终,它们会输出两个结果:一个高信号总结评论,和一个具体代码位置的inline评论。 也就是说,你打开PR时,就能看到一份AI评审报告,看到真正重要的问题,而不是几十页的流水账。 “AI写代码,AI评审”的时代,终于还是来了。  Claude自我循环、自我递归,苗头出现了。    随着AI能力日益强大,以后人类唯一的作用可能就是打开AI开关了,键盘上只需要Claude按键了。  多Agent系统,Claude Code评审军团出动 Claude Code Review最大的特点就是,它不是一个AI,而是一个团队。 当一个PR被创建时,系统会自动启动一支AI Agent团队。 据介绍,Claude新的代码评审功能会派出多个AI“评审智能体”并行工作,每个智能体负责不同类型的检查。  这些智能体通过验证来过滤误报,并根据严重性对错误进行排序。最终结果会作为一条高信号的综合评语,以及针对特定错误的内联评论,呈现在PR上。 评审规模会随PR大小调整。 大型或复杂的变更会获得更多智能体和更深入的审阅;微小的变更则会快速通过。根据Anthropic的测试,平均评审时间约为20分钟。 最终,通过多Agent相互验证,就可以减少误报。 这个过程中,它会重点查找逻辑错误、安全漏洞、边界条件(edge case)缺陷和隐蔽的回归问题。 所有发现的问题都会按严重等级(severity) 标记。  红色圆点表示普通问题,即合并代码前应修复的bug; 黄色圆点表示轻微问题,建议修复,但不会阻止合并; 紫色圆点表示既存问题,非本次PR引入的bug。 每条评审评论还包含一个 可折叠的推理说明(extended reasoning)。 展开后,你可以看到: Claude 为什么标记该问题 它是如何验证这个问题确实存在的 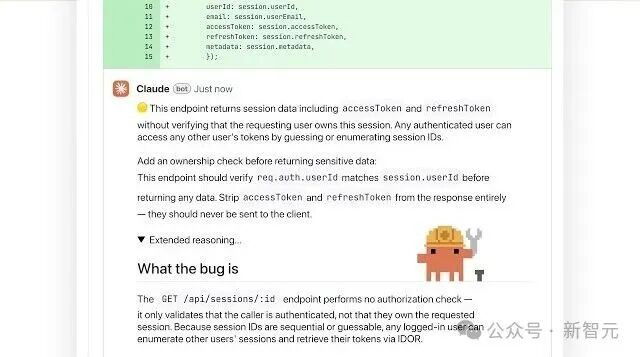 需要注意的是,这些评论不会自动批准或阻止PR合并,因此不会破坏现有的代码评审流程. 默认情况下,Claude Code Review主要关注代码正确性(correctness)。 也就是说,它重点检查: |






Copyright © 1999 - 2026 by Sinoquebec Media Inc. All Rights Reserved 未经许可不得摘抄 | GMT-4, 2026-7-20 05:49 , Processed in 0.134124 second(s), 23 queries .


















